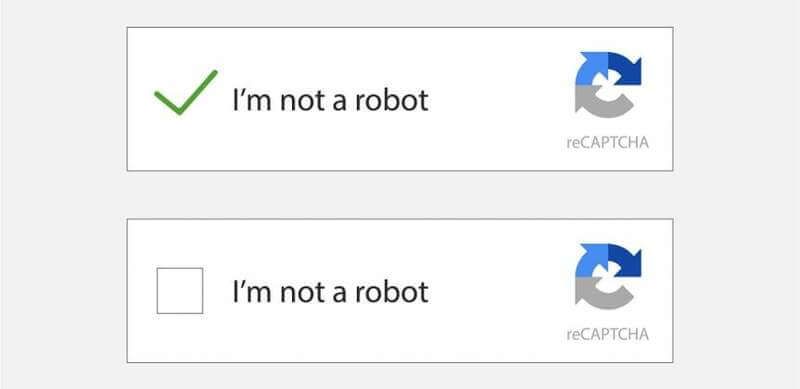
在登入部分網站時,應該絕大多數的人都見過「我不是機器人」的字句,要求使用者剔指定方格才能進入。不過大家在剔方格時,有沒有曾提出疑問,為什麼剔「我不是機器人」就能證明自己不是呢?原來Google這套驗證系統,比我們想像的更有趣和厲害,早在你剔選前已經辨認到你是否 Bot。
在「我不是機器人」驗證方法前,更常使用「扭曲文字」和選擇指定圖片兩種驗證,而開發這一套系統的「reCAPTCHA」,更利用每日數以億計的驗證次數,集全球電腦使用者之力,完善電子書和Google Maps數據。沒想到一套驗證系統,背後原來還有這一層意義。
日本作家井上マサキ就曾訪問了一位資工教授大久保隆夫,提及上網常見的網路認證方法,對於需勾選「我不是機器人」的行為,教授解答其中的有趣真相。
教授強調這系統並非「認證」而是「辨識」,因為「我不是機器人」只能辨識使用者是真的還是機器人,並不能認證是否為本人。而這類的「辨識」系統已經過幾代,用戶應該都還記得「扭曲文字」吧?明明輸入文字比勾選「我不是機器人」更複雜,但為何主流是「我不是機器人」呢?
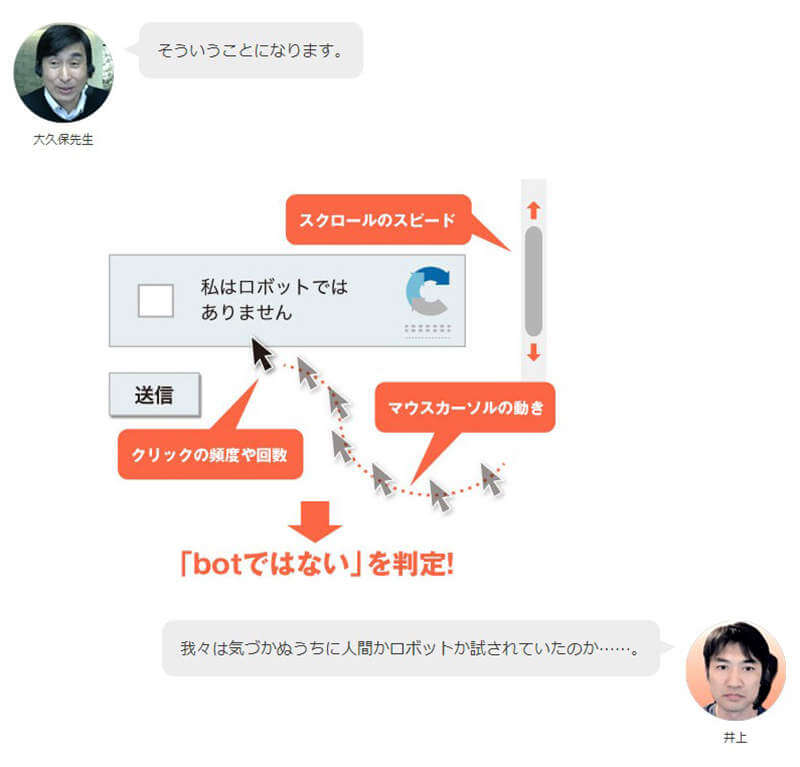
教授解釋,原來系統早在勾選前就已經辨識到你是不是真人,使用者在移動滑鼠的軌跡、拉動頁面的速度以及點擊的頻率和次數等,才是系統分析的重點。
只要勾選我不是機器人,使用者就會傳送一組資料到Google,包括IP位置、國家、時間,以及勾選的遊標軌跡,用來分析使用者。教授指出,由於AI技術的進步,「扭曲文字」以及「選擇指定圖片」等辨識方法已經被 Bot 破解,所以現時不少的網站會要求要多重辨識,如勾選「我不是機器人」後再「選擇指定圖片」。
驗證碼「CAPTCHA」在2003年就由Luis Von Agn的團隊共同開發,目的是用「CAPTCHA」防止使用者一次寄出大量的垃圾郵件,以及阻止「黃牛們」用 Bot 搶演唱會門票或其他限量商品。
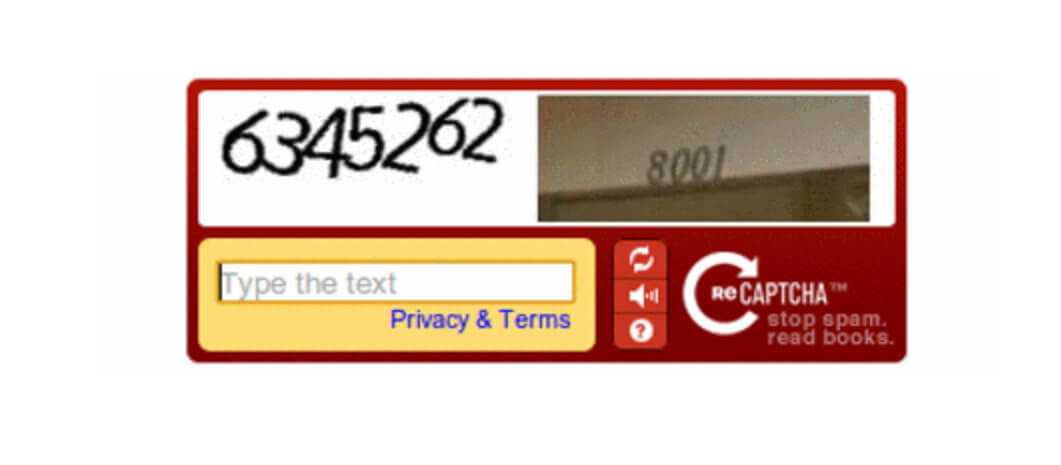
第一代「CAPTCHA」系統就是「扭曲文字」,目的是避免被搭載光學辨識的 Bot 自動分析出來,而「扭曲文字」不是隨機抽出來的,Luis Von Agn團隊利用「CAPTCHA」打算完成「讓全球電腦用戶協助數位化書本」的計畫。
驗證碼即是光學掃描分析不到的文字,當同一組字被多個使用者輸入相同答案時,該組字就會被確認並上傳到電子書數據庫。由於每年有一億組字詞被輸入,等同每年可產出250萬本書。
而「reCAPTCHA」右下角可看到Luis Von Agn團隊的目標:「Stop Spam, Read Books」(停止垃圾郵件,看書吧)。
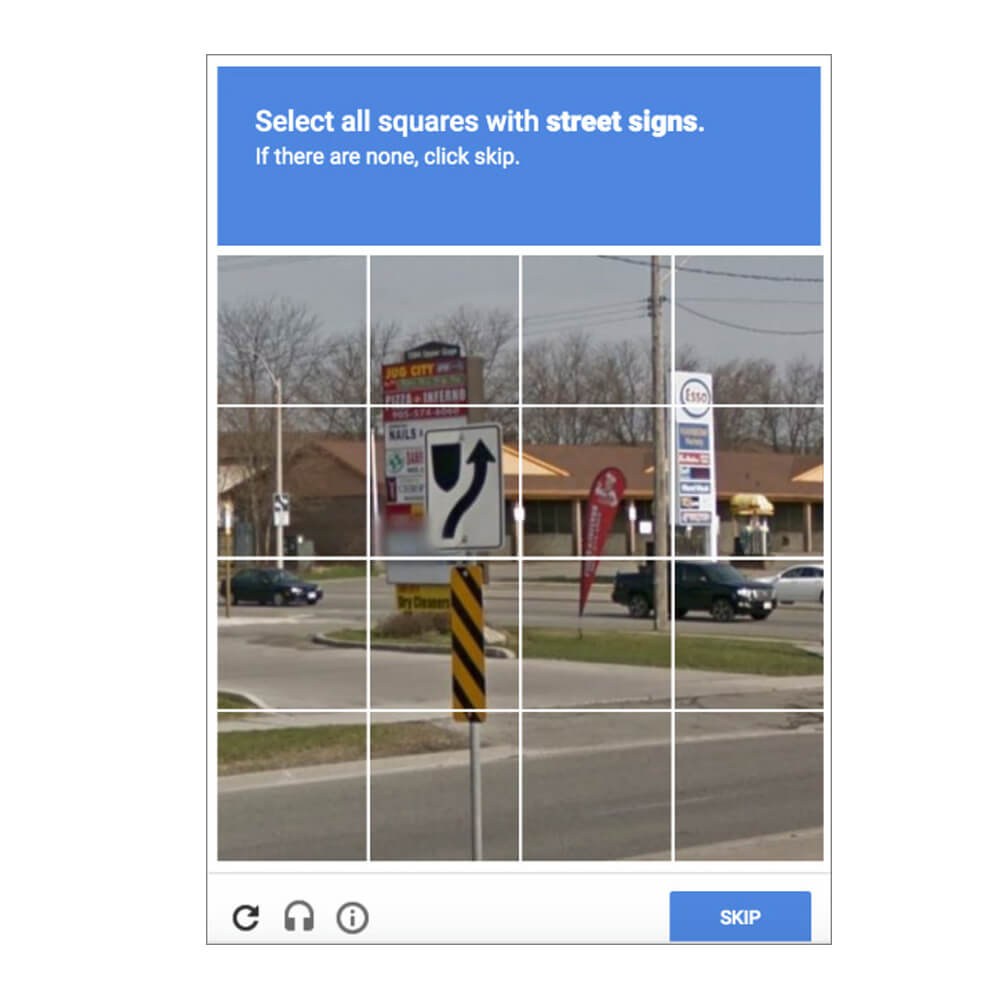
2009年Google收購「reCAPTCHA」利用驗證碼是數位化18世紀以來的《紐約時報》和Googel Books。Google再把「reCAPTCHA」的系列延伸到Google Maps中,也就是第二代的「reCAPTCHA」,點選指定圖片。讓使用者分析接景的紅綠燈、斑馬線、街道號碼等,完善Google Maps的數據。
隨著AI的進步,「扭曲文字」的AI輸入準確定更勝真人,於是Google就開發出第三代的「eCAPTCHA」,名為「noCAPTCHA reCAPTCHA」,不需要再輸入驗證碼,只要勾選「我不是機器人」即可。
文章授權轉載自《香港01》,原文刊於「數碼生活」請勿任意轉載
文章由 科學最前線 整理製作,請勿任意轉載
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}